

XPath is a powerful tool that allows Selenium testers to select elements on a web page using a variety of criteria, such as element type, attributes, and position in the HTML document. With XPath, testers can write precise and flexible scripts that can adapt to changes in the web page layout or content.
In this blog post, we will provide a detailed guide on how to use XPath in Selenium.
What is XPath?
XPath is a query language used for selecting elements from an XML or HTML document. It is extensively used in Selenium for locating web elements on a web page.
In simple terms, XPath is like a map that helps Selenium to identify specific elements on a webpage. It is a path expression that selects nodes or sets of nodes in an XML or HTML document. Using XPath, you can locate elements based on their attributes like name, id, class, etc. You can also traverse the elements in the XML or HTML tree structure even when there are no unique identifiers. XPath can handle dynamic elements that change frequently and can locate elements even when the DOM structure changes.
XPath Syntax
The syntax of XPath consists of a combination of tag names, attributes, and values that allow testers to identify and locate specific elements on a web page.
//tagname[@Attribute='Value']
- //:
The double forward slash “//” at the beginning of the expression indicates that the search should start at the root of the HTML document and match any element that meets the specified criteria. - Tagname:
“tagname” refers to the name of the HTML tag for which we want to select elements. Examples of common tag names are ‘div’, ‘span’, ‘input’, ‘select’, etc. - @Attribute:
“@Attribute” refers to the name of the attribute that we want to use to identify the element. Examples of common attributes are ‘id’, ‘class’, ‘name’, ‘type’, etc. - Value:
“‘Value'” refers to the specific value of the attribute that we want to use to identify the element. The value is enclosed in single or double quotes.
Types of XPath
There are two types of XPath expressions that can be used in Selenium:
1. Absolute XPath
Absolute XPath expressions specify the complete path of an element from the root node to the desired element. Absolute XPath expressions start with a forward slash (/) and list all the parent elements of the desired element, separated by forward slashes. For example, an absolute XPath expression to locate the “Sign In” button on the Google homepage might look like this:
/html[1]/body[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[2]/a[1]
This expression specifies the complete path of the input element, starting from the root HTML element.
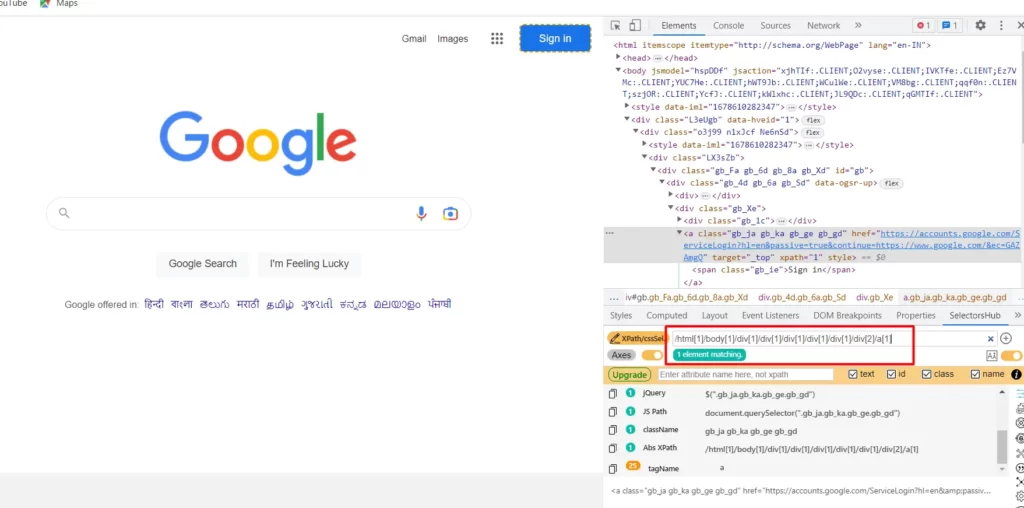
Practical Demonstration of Absolute XPath
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class AbsoluteXPathExample {
public static void main(String[] args) {
// Create a new instance of the ChromeDriver
WebDriver driver = new ChromeDriver();
// Navigate to the Google homepage
driver.get("https://www.google.com/");
// Find the Sign in button using the absolute XPath
WebElement signInButton = driver.findElement(By.xpath("/html[1]/body[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[2]/a[1]"));
// Click the Sign in button
signInButton.click();
// Close the browser
driver.quit();
}
}
2. Relative XPath
Relative XPath expressions specify the path of an element relative to its parent element or any other element on the page. Relative XPath expressions start with two forward slashes (//) and specify the desired element based on its attributes or other properties. For example, a relative XPath expression to locate the “Google Apps” icon on the Google homepage might look like this:
//a[@aria-label='Google apps']
This expression specifies the input element based on its aria-label attribute, regardless of its position in the HTML document.

Practical Demonstration of Relative XPath
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class RelativeXPathExample {
public static void main(String[] args) {
// Create a new ChromeDriver instance
WebDriver driver = new ChromeDriver();
// Navigate to the Google homepage
driver.get("https://www.google.com/");
// Find the Google Apps icon using a relative XPath expression
WebElement googleAppsIcon = driver.findElement(By.xpath("//a[@aria-label='Google apps']"));
// Click the Google Apps icon
googleAppsIcon.click();
// Quit the browser
driver.quit();
}
}
XPath Functions
XPath functions are built-in functions that can be used to manipulate and compare values in XPath expressions. Here are some common XPath functions that can be used in Selenium:
I. text():
The text() function is used to extract the text content of an element.
//div[@class='myclass']/text()
II. contains():
The contains() function is used to check if an attribute contains a specific value.
//div[contains(@class,'myclass')]
III. starts-with():
The starts-with() function is used to check if an attribute starts with a specific value.
//a[starts-with(@href,'http://')]
IV. position():
The position() function is used to find the position of an element within its parent.
//div[@class='myclass']/p[position()=2]
V. last():
The last() function is used to find the last occurrence of an element within its parent.
//div[@class='myclass']/p[last()]
VI. normalize-space():
The normalize-space() function is used to remove any leading and trailing whitespace from a string and collapse any internal whitespace to a single space character.
normalize-space(//div[@class='myclass']/p[1])
VII. and():
The and() function is used to combine two or more boolean expressions with a logical AND operator.
//input[@type='text' and @name='username']
This will match any input element with type ‘text’ and name ‘username’.
VIII. or():
The or() function is used to combine two or more boolean expressions with a logical OR operator.
//input[@type='text' or @type='password']
This will match any input element with type ‘text’ or type ‘password’.
XPath Axes Methods
In addition to XPath functions, Selenium also supports XPath axes methods, which allow us to select elements based on their relationship to other elements in the HTML document. Some of the most commonly used XPath axes methods in Selenium are:
I. ancestor:
The ancestor axis selects all ancestors (parent, grandparent, etc.) of the current element.
//div[@class='myclass']/ancestor::body
This will select the body element that is an ancestor of the div element with class ‘myclass’.
II. descendant:
The descendant axis selects all descendants (children, grandchildren, etc.) of the current element.
//div[@class='myclass']/descendant::p
This will select all p elements that are descendants of the div element with class ‘myclass’.
III. following:
The following axis selects all elements that come after the current element in the document order.
//div[@class='myclass']/following::p
This will select all p elements that come after the div element with class ‘myclass’.
IV. following-sibling:
The following-sibling axis selects all siblings that come after the current element.
//div[@class='myclass']/following-sibling::div
This will select all div elements that are siblings of the div element with class ‘myclass’ and come after it.
V. parent:
The parent axis selects the parent of the current element.
//p[@class='myclass']/parent::div
This will select the div element that is the parent of the p element with class ‘myclass’.
VI. child:
The child axis selects all children of the current element.
//div[@class='myclass']/child::p
This will select all p elements that are children of the div element with class ‘myclass’.
VII. preceding:
The preceding axis selects all elements that come before the current element in the document order.
//p[@class='myclass']/preceding::div
This will select all div elements that come before the p element with class ‘myclass’.
VIII. preceding-sibling:
The preceding-sibling axis selects all siblings that come before the current element.
//div[@class='myclass']/preceding-sibling::div
This will select all div elements that are siblings of the div element with class ‘myclass’ and come before it.
IX. self:
The self axis selects the current element.
//p[@class='myclass']/self::p
This will select the p element with class ‘myclass’ itself.
Advantages of XPath
Following are some of the key advantages of XPath:
I. Flexibility:
XPath allows you to select elements on a web page using a wide range of criteria, including tag name, attribute, value, position, and more. This makes it possible to create highly precise selectors that can locate even the most complex elements on a web page.
II. Expressive syntax:
The syntax of XPath is concise and expressive, making it easy to create complex selectors using a combination of tag names, attributes, and values. This makes it easier for you to write and maintain test scripts, as they can quickly and easily understand the selectors being used.
III. Consistency:
XPath selectors are consistent across different browsers and platforms, making it possible to create test scripts that work reliably across multiple environments. This makes it easier for you to create automated tests that can be run on different machines or in different testing environments.
IV. Compatibility:
XPath is supported by all major web browsers and can be used together with a wide range of programming languages and testing frameworks. This makes it a highly versatile language that can be used in a variety of testing scenarios.
V. Performance:
XPath selectors can be faster than other types of selectors, such as CSS selectors, when used to locate complex elements on a web page. This is because XPath can take advantage of the full structure of the HTML document to locate elements, rather than relying solely on the location of the element in the DOM tree.
Conclusion
In conclusion, XPath is a powerful language that can be used to locate elements on a web page with great precision and flexibility. By using XPath selectors in conjunction with Selenium, testers can create automated tests that are reliable, efficient, and compatible with a wide range of platforms and browsers.
In this blog, we’ve covered the basics of XPath syntax, including the different types of selectors, functions, and axes available. We’ve also explored the advantages of using XPath for web testing, including its flexibility, expressiveness, consistency, compatibility, and performance.